Key Takeaways
- At Baymard we’ve tested ChatGPT-4’s ability to conduct a UX audit of 12 different webpages, by comparing the AI model’s UX suggestions to those of a qualified human UX professional
- Our tests show that ChatGPT-4 has an 80% false-positive error rate and a 20% accuracy rate in the UX suggestions it makes
- When compared to the human experts, ChatGPT-4 discovered 26% of the UX issues in the screenshot of the webpage, and just 14% of the UX issues actually present on the live webpage (as interaction-related UX issues cannot be ascertained from an image)
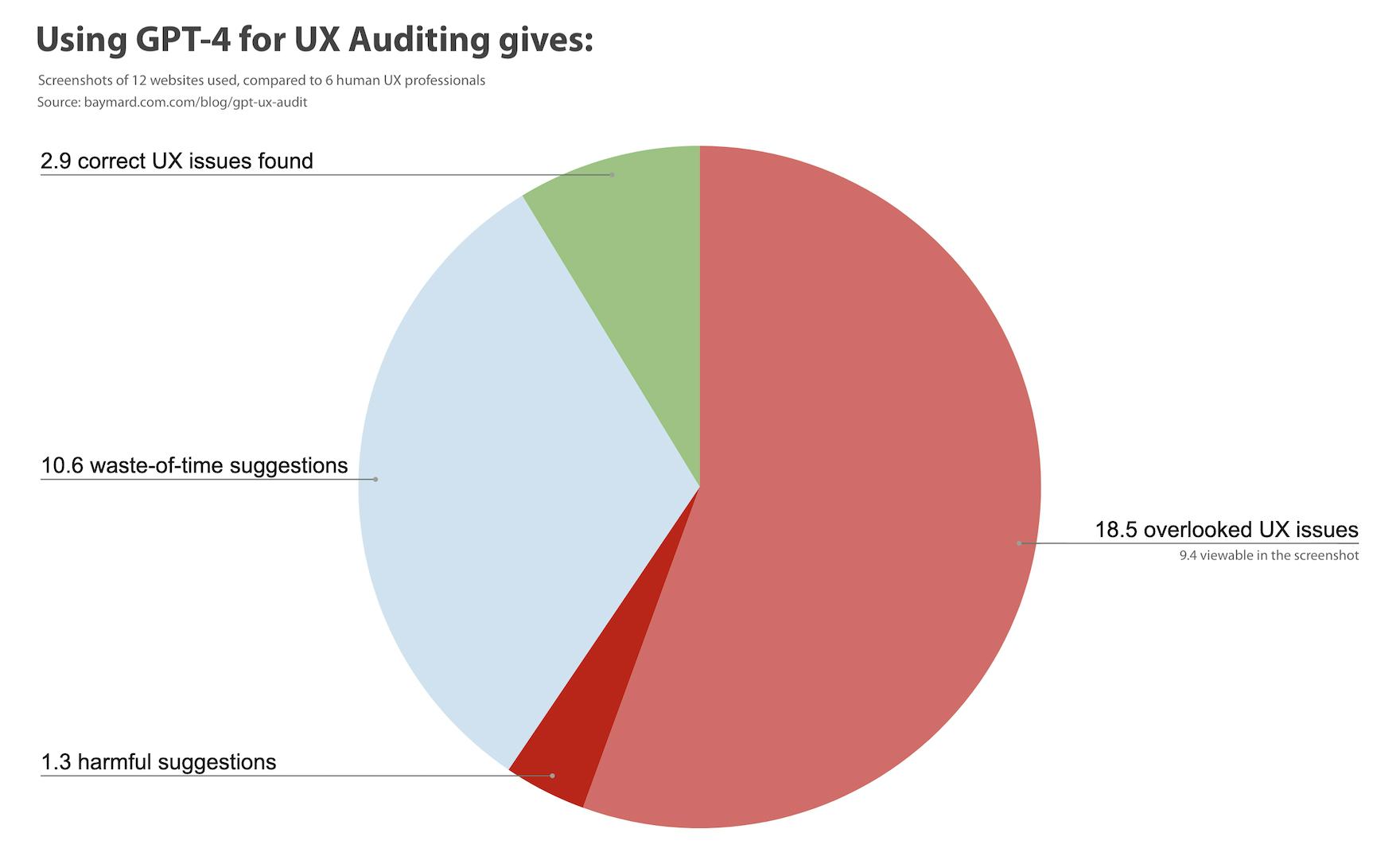
- On the 12 webpages tested, GPT-4 on average: correctly identified 2.9 UX issues, but then overlooked 18.5 UX issues on the live webpage and 9.4 UX issues in the screenshot of the webpage, came up with 1.3 suggestions that are likely harmful to UX, and made 10.6 suggestions that are a waste of time (when compared to a human UX professional)
- The human experts used in our testing were 6 different highly trained UX benchmarkers working at Baymard (relying on our 130,000+ hours of large-scale UX research)
Why This Test?
OpenAI recently opened up access for image upload in ChatGPT-4. This allows anyone to upload a screenshot of a webpage and ask, “What UX improvements can be made to this page?”. This gives a seemingly impressive response, where the results are clearly tailored to the webpage screenshot uploaded, and with a tone of high confidence.
We decided to test how accurate GPT-4 actually is when it comes to discovering UX issues on a webpage — to get a better understanding of how far the AI model is from a qualified human conducting a UX audit of the same webpage.
Test Methodology
1 of 12 webpage screenshots analyzed (full version here).

GPT-4’s response for the uploaded webpage screenshot.
GPT was compared to the results of a human UX professional spending 2-10 hours analyzing the same page.
We uploaded a screenshot of 12 different e-commerce webpages to GPT-4 and asked, “What UX improvements can be made to this page?”. We then manually compared the responses of GPT-4 with 6 human UX professionals’ results for the 12 very same webpages.
The humans are 6 different highly trained UX benchmarkers working at Baymard who are all relying on the results of Baymard’s 130,000+ hours of large-scale UX testing of more than 4,400+ real end users (see more at baymard.com/research).
The humans spent 2–10 hours on each of the 12 webpages (this was performed as part of past UX benchmarking work). We spent an additional 50 hours on a detailed line-by-line comparison of the humans’ 257 UX suggestions against ChatGPT-4’s 178 UX suggestions.
The 12 webpages tested were a mix of product pages, product listings, and checkout pages at: Lego, Cabelas, Argos, Overstock, Expedia, REI, Thermo Fisher, TireRack, Zalando, Sigma Aldrich, Northern Tool, and Cructhfield.
(Note: other prompts were also tested but they gave largely the same responses.)
The Results
Below are the results of analyzing the 12 pages, 257 UX issues identified by humans, and 178 UX issues identified by ChatGPT-4.
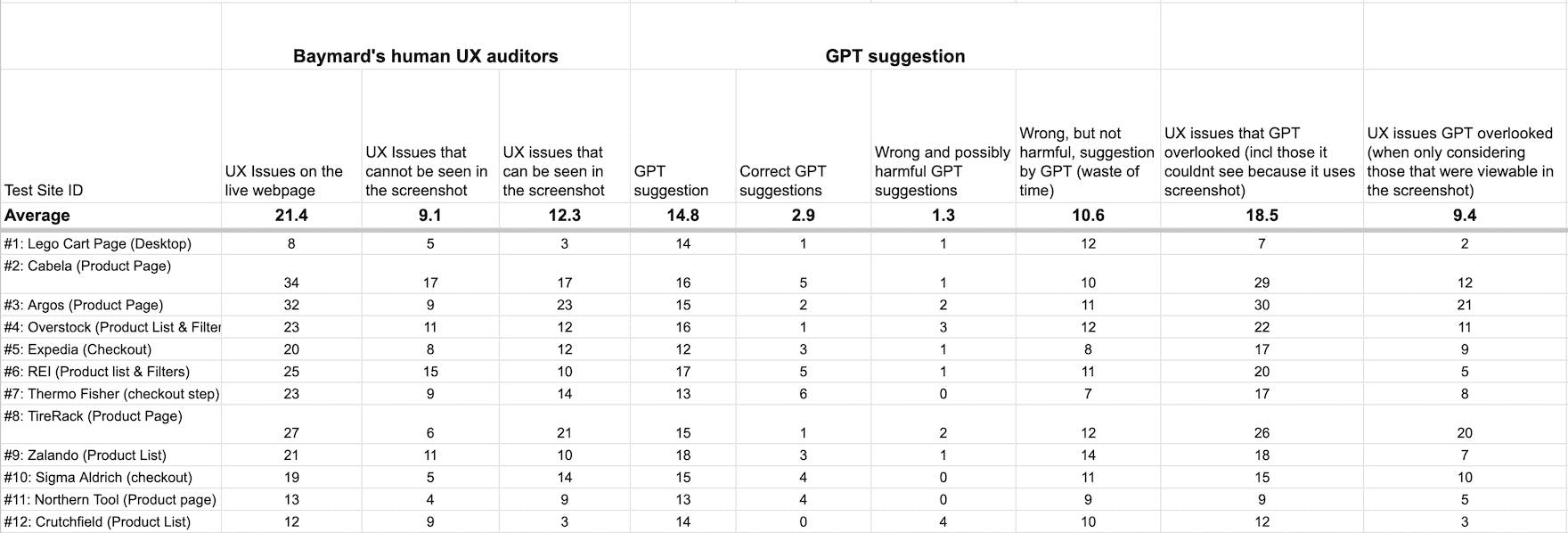
The results give the following GPT-4 discovery-, accuracy-, and error-rates:
- 14.1% UX discovery rate overall (on the live webpage)
- 25.5% UX discovery rate for only issues seen in the screenshot
- 19.9% accuracy rate of the GPT suggestions
- 80.1% false-positive error rate of GPT suggestions (overall)
- 8.9% false-positives where GPT suggestions are likely harmful
- 71.1% false-positives where GPT suggestions are a waste of time
(The above percentage stats have been rounded in the rest of the article).
GPT-4 Discovers 26% of UX Issues in the Screenshot, and 14% of UX Issues on the Webpage
Our tests show that GPT-4 discovered 26% of the UX issues verified to be present in the screenshot of the webpage, when compared to a human UX professional.
If we want to understand how a human UX professional compares to the method of ‘giving ChatGPT-4 a screenshot of a webpage’, then we need to instead consider all UX issues the human identified using the live webpage. Here, ChatGPT-4 discovered 14% of the UX issues actually present on the live webpage, because GPT-4 here only analyzed screenshots of the webpage, compared to the human UX professionals who used the live interactive website.
Uploading screenshots of a webpage and asking any AI model to assess it will always be a greatly limiting method, as a very large portion of website UX issues are interactive in nature. Discovering many of the UX issues present on a given webpage requires interacting with the webpage (e.g., click buttons, hover images, etc.) but also requires that one navigates between pages and takes information from other pages into account when assessing the current page.
Being able to truly navigate and click around websites, will likely lift the discoverability rate of UX issues from 14% close to 26%. That of course still means overlooking 3 out of 4 UX issues on the given webpages (or, in absolute numbers, overlooking 10.6 UX issues per page).
(In comparison, heuristic evaluations are often said to have a 60% inter-rater reliability, and at Baymard we’ve found that this can be pushed to 80–90% with the right heuristics, training, and technologies.)
The 80% Error Rate: 1/8 Is Harmful, and 7/8 Is a Waste of Time
ChatGPT-4 had a 80% false-positive error rate.
Of these errorful suggestions around 1/8 of were advice that would likely be harmful to UX. For example:
- GPT suggested LEGO, which already have a simplified footer, to simplify it further (essentially removing it)
- GPT suggested Overstock, that uses pagination, to instead “either use infinite scrolling or ‘load more” (infinite scrolling is observed to be harmful to UX, whereas ‘load more’ is a good suggestion)
The vast majority of the errorful UX suggestions made by GPT-4 (7/8) were however not harmful, but simply a waste of time; typical examples observed:
- GPT very often made the same overly generic suggestions based on things not viewable in the screenshot. For example, for all 12 webpages, it suggested: “Make the site mobile responsive…” despite clearly being provided a desktop screenshot
- GPT made several suggestions for things the site already had implemented, e.g. suggesting to implement breadcrumbs for REI’s product page, when the site clearly already have this
- GPT made suggestions for unrelated pages, e.g. for Argos’ product page one of the suggestions was “While not visible in the current screenshot, ensuring the checkout process is as streamlined and straightforward as possible can further improve the user experience
- Some of the suggestions by GPT were also so inaccurate that it’s unclear what is meant, e.g. GPT suggested for TireRack’s product details page that: “Instead of static images, an image carousel for the tire and its features might be more engaging and informative.” (the site already has a PDP image gallery, so this advice is prone to be interpreted as an auto-rotating carousel, which would be harmful)
- GPT also made some outdated suggestions based on UX advice that used to be true, but in 2023 is no longer valid due to an observed change in general user behavior (e.g., our 2023 UX research shows that users’ understanding of checkout inputs have improved greatly, compared to what we have observed in the past 10 years)
In Summary: ChatGPT-4 Is Not (Yet) Useful for UX Auditing
In the UX world, large language models like ChatGPT are increasingly proving as indispensable work tools, e.g., for analyzing large datasets of qualitative customer support emails, brainstorming sale page copy ideas, and transcribing videos. It’s also impressive that this technology can now interpret a screenshot of a webpage.
However, when it comes to having GPT-4 help with performing UX audits, we would caution against it because:
Of the 12 webpages tested, GPT-4 on average correctly identified 2.9 UX issues, but then overlooked 18.5 UX issues on the live webpage, 9.4 UX issues in the screenshot of the webpage, made 1.3 suggestions that would be harmful to UX, and gave 10.6 suggestions that would be a waste of time.
This means that ChatGPT-4 is very far from human performance — assuming the human is skilled in UX, has 2–10 hours per page type, and uses a comprehensive database of UX heuristics.
It’s especially the combination of ChatGPT-4’s low discoverability rate of UX issues and the low accuracy rate of its suggestions that’s problematic. Even as a “quick free UX check”:
- It simply will not find enough of the UX issues present on the live webpage/screenshot of the webpage (respectively a 14% and 26% discoverability rate)
- Additionally, work is required to parse its response to identify the correct UX suggestions, among the errorful suggestions. With an accuracy rate of 20%, this is not “a useful supplemental tool that will give you a fifth of UX issues for free” as it will require a human UX professional to parse
Furthermore, considering the cost of implementing any website change (design and development), basing website changes on a UX audit of this low quality is bound to yield a poor overall return of investment.
Getting access: our research findings are available in the 650+ UX guidelines in Baymard Premium – get full access to learn how to create a “State of the Art” e-commerce user experience.
If you want to know how your desktop site, mobile site, or app performs and compares, then learn more about getting Baymard to conduct a UX Audit of your site or app.